




I. Présentation▲
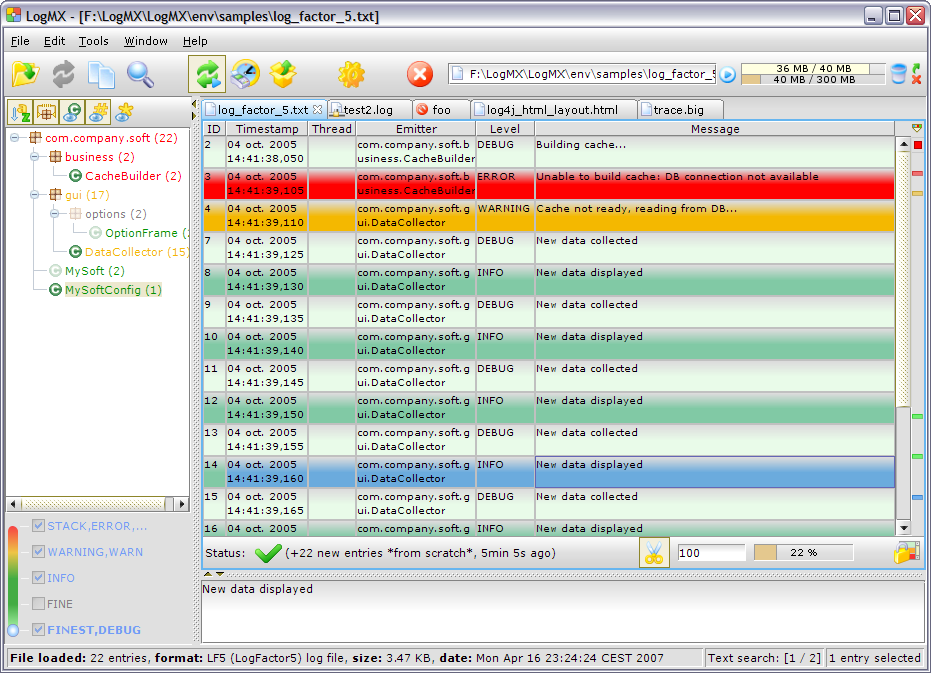
LogMX est un outil Java permettant la visualisation et l'analyse de n'importe quel fichier de log ou trace.
Il ne se contente pas d'afficher le texte du fichier, mais le parse afin de présenter à l'utilisateur la liste des entrées du fichier et l'arborescence des émetteurs de ces entrées. L'utilisateur peut alors filtrer ces entrées par émetteur et/ou niveaux de logs. Si le format du fichier n'est pas reconnu, l'utilisateur peut décrire son format dans les options de LogMX ou développer une classe Java (pour un format complexe) afin que LogMX puisse le parser.
II. Fonctionnalités▲
Compatible avec tous les formats de log/trace
LogMX gère par défaut les formats Log4j et LogFactor5, mais il est possible de lui « apprendre » n'importe quel autre format. Lors de l'ouverture d'un fichier, il détecte automatiquement son format. Dans le cas où le format n'est pas reconnu, le contenu du fichier est affiché comme simple texte brut (l'utilisateur peut alors décrire le format utilisé afin de profiter des fonctionnalités de LogMX).
Accède aux fichiers locaux et distants
La version d'évaluation permet d'accéder aux fichiers locaux, ainsi qu'aux fichiers distants via le protocole SCP. La version professionnelle permet elle d'accéder à n'importe quel contenu via des plugins Java développés par l'utilisateur (ex. : FTPS, POP3, base Oracle…).
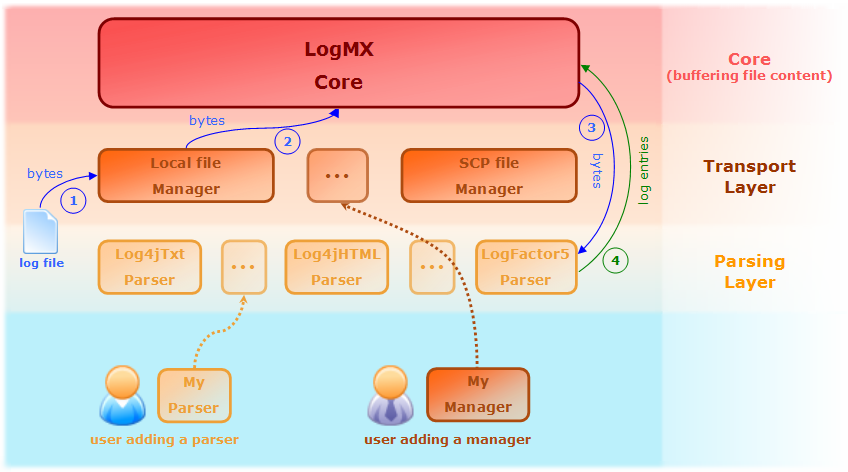
Voici un schéma synthétique de l'architecture de LogMX permettant de mieux comprendre comment il peut gérer n'importe quel format depuis n'importe quelle source de données (schéma en anglais, car provenant du site officiel) :
Fonction Autorefresh
Quand le mode 'Autorefresh" est activé, le contenu du fichier est affiché en temps réel (à chaque modification de fichier, il parse les nouvelles entrées de log uniquement). Il est possible de n'afficher que les N dernières entrées du fichier afin d'économiser la quantité de RAM utilisée. Une jauge affiche en temps réel la quantité de mémoire actuellement utilisée par LogMX par rapport à la quantité maximum utilisable (spécifiée avec -Xmx).
Filtrage par émetteurs/niveaux
L'utilisateur peut facilement filtrer les entrées de log par émetteur(s) et/ou niveau(x) de logs. Il est par exemple possible de n'afficher que les logs émis par la classe « com.company.soft.MyClass », le package « com.company.soft.gui », ou bien encore les logs émis par n'importe quelle classe sauf « com.company.soft.MyClass ». De même, les entrées de log d'un certain niveau de log peuvent être affichés / masqués : il est par exemple possible de n'afficher que les logs de niveau INFO et plus critique (i.e. tous niveaux sauf DEBUG), ou bien uniquement les logs de niveau WARNING. Bien entendu, il est possible de cumuler des filtres d'émetteurs avec des filtres de niveaux.
Gestion de tous les niveaux de log/trace
L'utilisateur peut déclarer un nouveau niveau de log et définir sa criticité et sa couleur (utilisée pour l'affichage des entrées de ce niveau). De même, il peut modifier la couleur et la criticité de tout niveau déjà existant (LogMX connaît par défaut tous les niveaux Log4j et Java logging API).
Alertes
LogMX permet à l'utilisateur de définir un ensemble « d'alertes » : sur l'apparition d'une certaine entrée de log (pattern décrit par l'utilisateur basé sur le message, l'émetteur, le niveau…) une alerte peut être levée : émission d'un son, exécution d'un programme externe, mise au premier plan de la fenêtre, ou envoi de mail.
Calculs temporels
L'utilisateur peut facilement connaître le temps écoulé entre deux entrées de log (pratique pour les benchmarks par exemple), ainsi que le temps écoulé depuis l'émission d'une entrée.
Autres fonctionnalités
LogMX inclut des fonctions de recherche (expressions régulières possibles), d'export au format CSV, et de flush ou suppression du fichier.
III. Utilisation▲
III-1. Filtrer les entrées de log▲
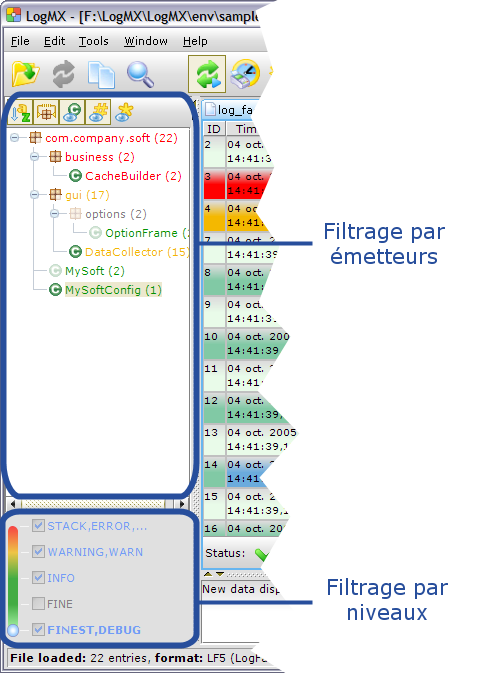
Comme vu ci-dessus, l'utilisateur peut filtrer les entrées de log par émetteurs et niveaux. Pour ce faire, il utilise les deux panels gauches ci-dessous :
III-1-1. Filtrage des émetteurs▲
Les 'émetteurs' attendus par LogMX sont de la forme « a.b.c ». Dans cet exemple, « a » et « b » sont des « packages » et « c » une classe (un package contient des nœuds fils, mais pas une classe). Ce formalisme permet de modéliser la structure hiérarchique des packages et classes de Java, mais également une structure « à plat » par exemple une liste de processus, services, ou démons (i.e. uniquement des 'classes' comme « ps », « sshd »…).
L'arborescence des émetteurs est affichée dans la partie supérieure gauche de la fenêtre. Pour filtrer un émetteur (package ou classe), il suffit de cliquer sur son icône (à gauche de son nom). Pour annuler ce filtrage, il suffit de cliquer à nouveau dessus. Le filtrage d'un package est par défaut récursif : tous les packages/classes fils sont également filtrés. Un clic droit sur un émetteur affiche un menu contextuel permettant : le filtrage non récursif, le filtrage de tous les émetteurs sauf celui-ci, et le filtrage de tous les émetteurs sauf celui-ci et ses fils.
Il est également possible de filtrer les émetteurs par un clic droit sur une entrée de log (un menu contextuel apparaît alors et permet des options de filtrage sur l'émetteur de cette entrée).
III-1-2. Filtrage des niveaux de log▲
La partie inférieure gauche de la fenêtre permet de filtrer des niveaux de log. Un clic sur un niveau activera ce niveau ainsi que les niveaux plus critiques, et filtrera les niveaux moins critiques (ex. : un clic sur WARNING activera ce level ainsi que ERROR, et filtrera les niveaux INFO et DEBUG). Il est également possible de filtrer ou activer n'importe quel niveau en cochant ou décochant la case à gauche de son nom. Par exemple, même si l'utilisateur clique sur WARNING puis décoche le niveau ERROR, seul le niveau WARNING sera actif.
Démo vers le filtrage
III-2. Entries outline▲
L'Entries Outline est la bande verticale située à l'extrémité droite de la fenêtre. Elle permet de visualiser tous les éléments marquants du fichier et d'y accéder par un simple clic (même fonctionnement qu'Eclipse) :
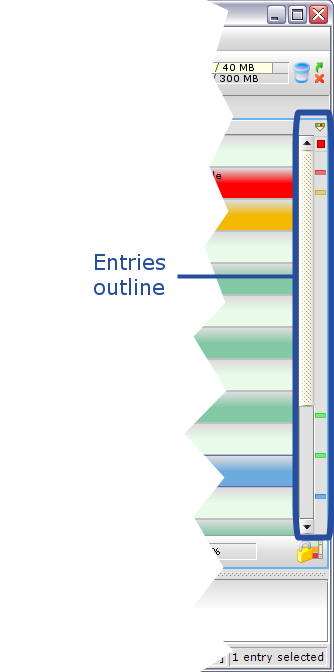
Les entrées de logs de niveaux maximal (i.e. les erreurs) ou maximal-1 (les warnings) y sont représentées par un point rouge et orange, respectivement. Les entrées trouvées à l'issue d'une recherche sont en bleu et les entrées « marquées » par l'utilisateur en vert. Bien entendu, tout le contenu du fichier est représenté sur la hauteur de la fenêtre (si une entrée de niveau ERROR est présente par exemple aux trois quarts du fichier, sa marque sera affichée aux trois quarts de la hauteur de l'Entries Outline). Il est possible, par un clic droit sur le haut de l'Entries Outline, de sélectionner les éléments à afficher (erreurs, warnings, entrées trouvées, entrées marquées).
Démo vers l'Entries Outline
III-3. Gérer les niveaux de logs et les parsers▲
III-3-1. Gestion des niveaux▲
Comme vu précédemment, LogMX peut gérer tous types de formats et niveaux de log, grâce à la possibilité pour l'utilisateur de définir ses propres formats et niveaux, directement dans la fenêtre des options de LogMX. Ici, par exemple, le gestionnaire des niveaux de logs :
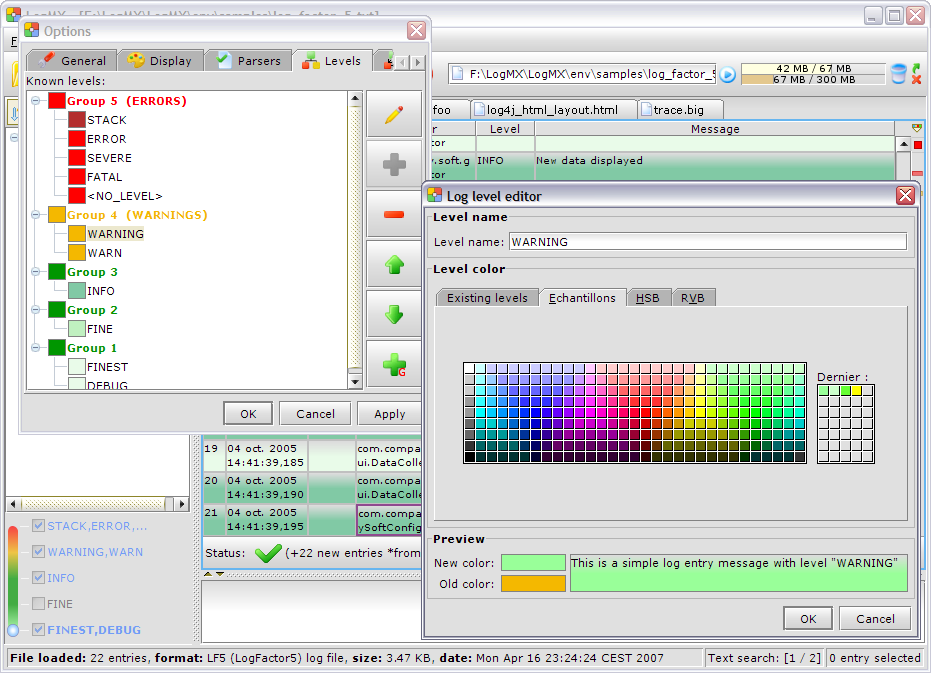
L'utilisateur peut modifier le nom, la couleur, et la criticité de chaque niveau, et peut également créer ou supprimer des niveaux (la couleur d'un niveau est utilisée pour afficher les entrées de ce niveau dans les fichiers). Chaque niveau appartient à un « Groupe de niveaux » d'une criticité donnée. Il est possible de créer autant de groupes que souhaité, sachant que le premier est le Groupe 1 et correspond au niveau de criticité la plus faible (ex. : DEBUG). Déplacer un niveau d'un groupe à l'autre permet donc de modifier sa criticité. Si l'utilisateur tente de déplacer un niveau plus haut que le dernier groupe ou plus bas que le premier, LogMX va automatiquement créer un nouveau groupe pour accueillir ce niveau. Par exemple, déplacer le niveau ERROR (du dernier groupe 5) vers le haut créera un nouveau groupe de criticité 6 contenant uniquement le niveau ERROR.
Dans l'arborescence des émetteurs et l'Entries Outline, les notions de « Errors » et « Warnings » sont présentes : il ne s'agit pas là de deux niveaux donnés, mais du Groupe de niveau maximal et du Groupe de niveau maximal-1 (resp.). Dans l'exemple donné ci-dessus, le niveau ERROR passé en Groupe 6 restera une « Error » pour LogMX, mais le niveau CRITICAL resté en Groupe 5 deviendra lui un « Warning ».
LogMX peut également gérer les formats de log ne contenant pas de niveau : il affecte à toute entrée sans niveau le niveau par défaut « ‹NO_LEVEL› » (niveau non supprimable par l'utilisateur, mais dont la criticité et la couleur peuvent être modifiées).
III-3-2. Gestion des parsers▲
De même que pour les niveaux de log, l'utilisateur peut ajouter, modifier, ou supprimer un 'parser'. Un 'parser' est ce qui permet à LogMX d'interpréter le contenu d'un fichier et d'en extraire les informations de chacune de ses entrées. Il existe à ce jour deux types de parsers LogMX :
- Parser Log4jPattern
Si l'utilisateur utilise la librairie Log4j pour générer ces logs, il lui suffit de spécifier à LogMX le pattern Log4j utilisé (celui décrit dans le fichier de configuration de log4j, par exemple « %6p (%F) - %m%n »). LogMX sera alors capable, avec ce parser, d'interpréter le contenu des fichiers générés par cette configuration Log4j.
Il est possible d'utiliser ce type de parser même si log4j n'est pas utilisé : il suffit de décrire le format de log utilisé avec le formalisme Log4j (une aide est disponible au sein de l'éditeur afin de présenter ce formalisme).
Afin d'aider l'utilisateur, la fenêtre d'édition d'un parser Log4jPattern permet de tester, à la volée le parsing de quelques lignes du fichier :
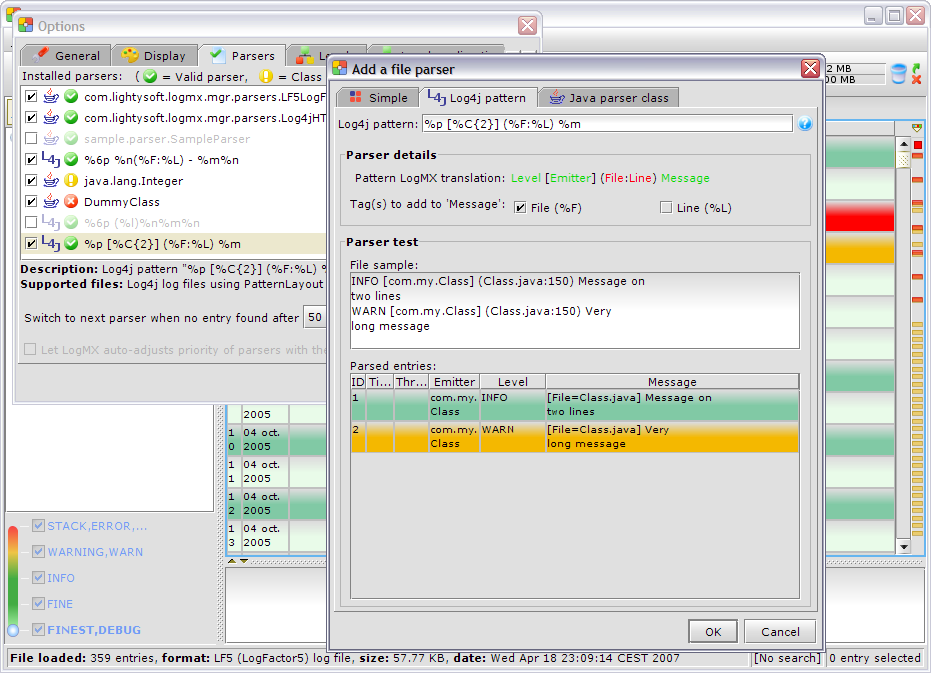
Notez qu'il est également possible d'inclure dans le message de log de l'entrée tout champ Log4j non géré en natif par LogMX (comme ici dans la capture d'écran le fichier source et la ligne ayant généré l'entrée de log).
- Parser JavaClass
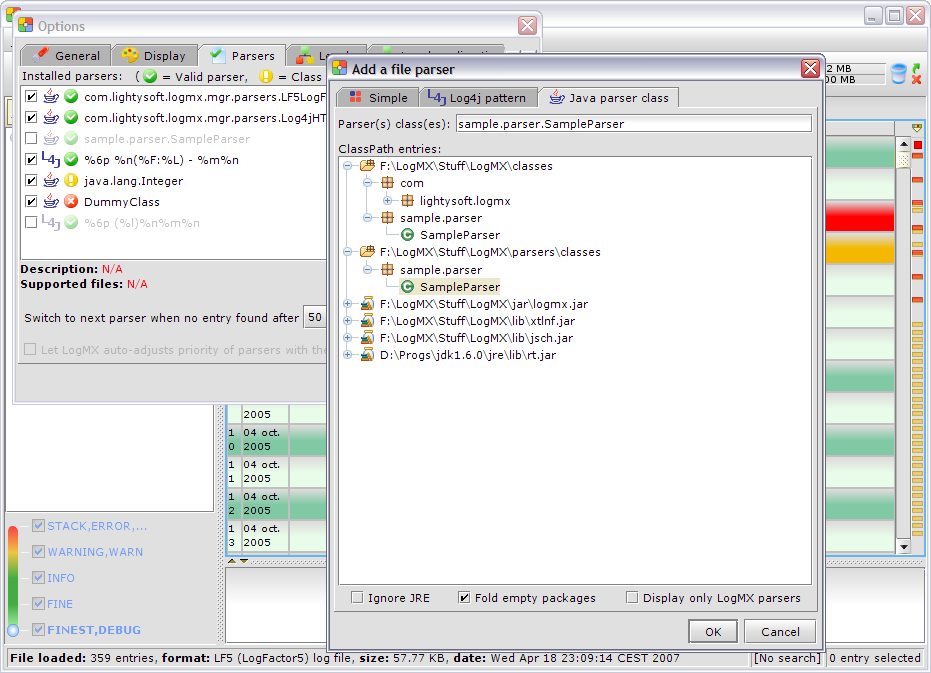
Afin d'offrir le maximum de possibilités, l'utilisateur peut implémenter un parser LogMX en écrivant une seule classe Java héritant d'une classe abstraite de LogMX. L'API (de petite taille) est documentée via une Javadoc fournie avec LogMX, et l'écriture de cette classe est guidée par l'obligation d'implémenter des méthodes abstraites, ainsi que par un exemple complet fourni. Ce genre de parser est utile en cas de format assez complexe (ex. : XML), ou des besoins accrus en performance (un parser spécifique à un seul format sera bien sûr plus performant, car optimisé pour celui-ci). Les environnements de développement pour Ant et Eclipse sont fournis avec LogMX, et il suffit d'utiliser le gestionnaire des parsers Java pour sélectionner la classe implémentée au sein de l'explorateur de ClassPath :
III-4. La recherche▲
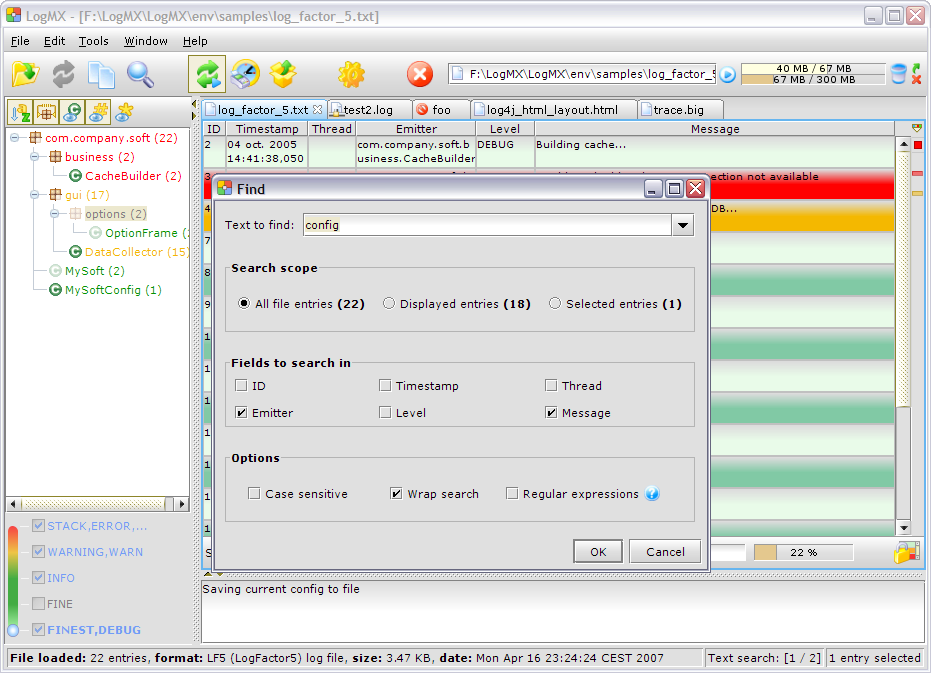
L'utilisateur peut rechercher une chaîne de caractères ou une expression régulière dans un fichier, ou dans un sous-ensemble du fichier. Il peut de plus restreindre cette recherche à certains 'champs' des entrées de log (ex.: date, thread, message…).
Une fois la recherche effectuée, les entrées trouvées sont représentées dans l'Entries Outline (cf. ci-dessus), et l'utilisateur peut alors parcourir ces entrées (par raccourci clavier ou par les options).
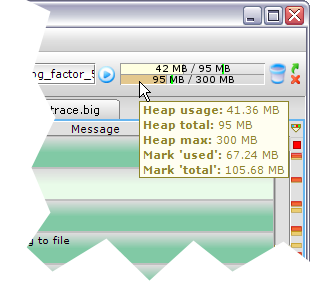
III-5. État de la mémoire▲
Afin de gérer au mieux l'analyse de fichiers de grandes tailles, deux jauges sont affichées en haut à droite et représentent l'utilisation actuelle de la mémoire : une jauge représente la quantité de mémoire utilisée par rapport à la quantité actuellement allouée, et l'autre jauge représente la quantité de mémoire actuellement allouée par rapport à la quantité maximale de mémoire allouable. Un bouton permet à tout moment d'exécuter le GarbageCollector afin de libérer immédiatement la mémoire inutilisée (la configuration par défaut de Java libère la mémoire uniquement quand cela est vraiment nécessaire).
Quand la quantité de mémoire disponible devient critique, les jauges sont colorées en rouge afin que l'utilisateur ferme certains fichiers inutilisés, ou augmente la quantité maximale de mémoire utilisable (option -Xmx dans le script de lancement).
IV. Liens▲
LogMXSite officiel de LogMX : Le site officiel de LogMX.
Vidéos de démoVidéos de démo : Les vidéos de démonstration de LogMX.
V. Remerciements▲
Je remercie tout d'abord Xavier Tello, l'auteur de LogMX, pour m'avoir autorisé à publier cet article et aidé lors de sa rédaction.
Je tiens à remercier les membres de developpez Hikage, Ricky81, UNi[FR] pour les conseils, remarques et relectures.
Je remercie aussi www.developpez.com me permettant de publier cet article et Nono40 pour ses outils.